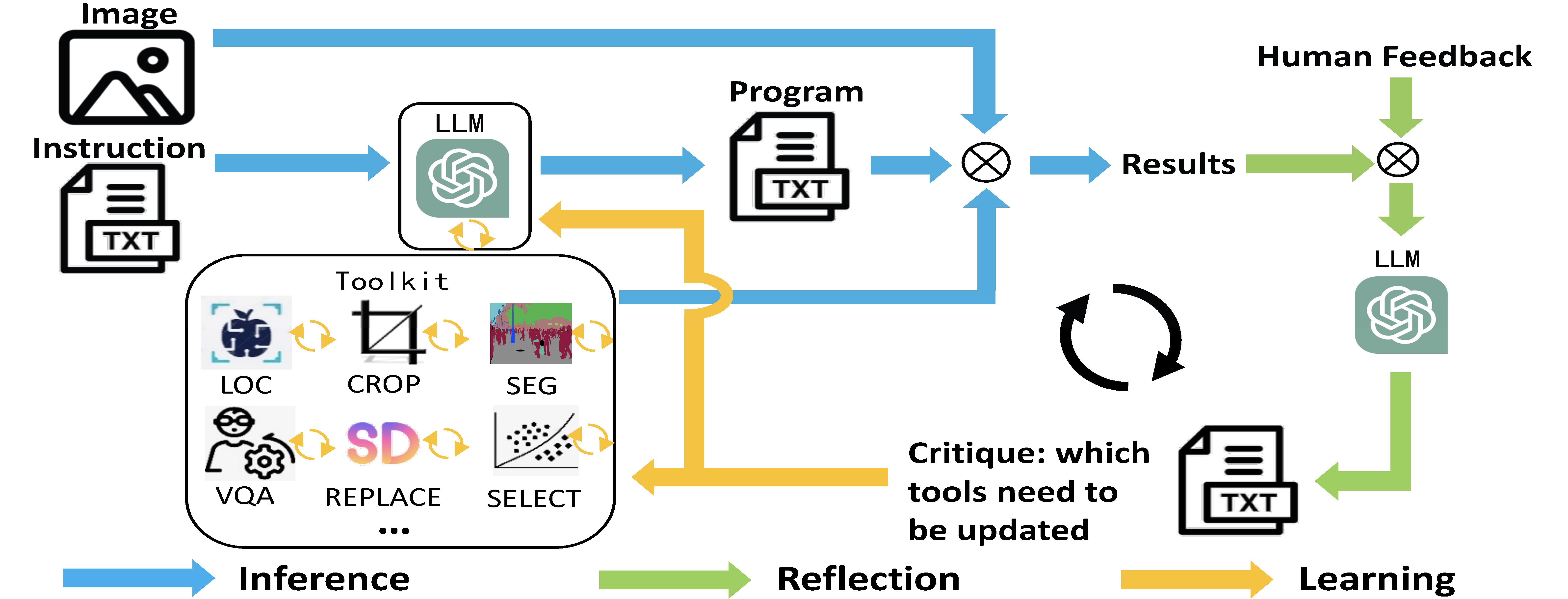
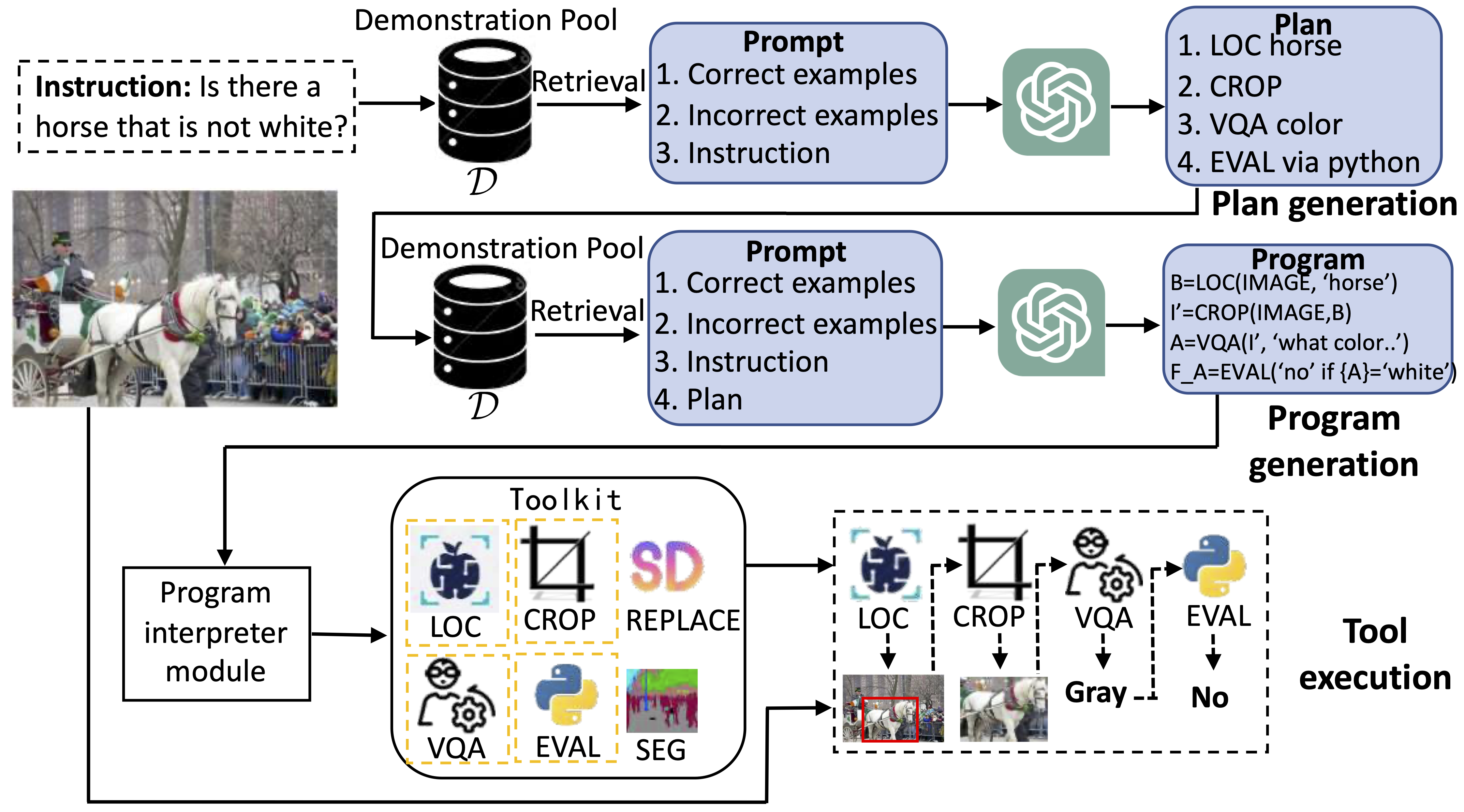
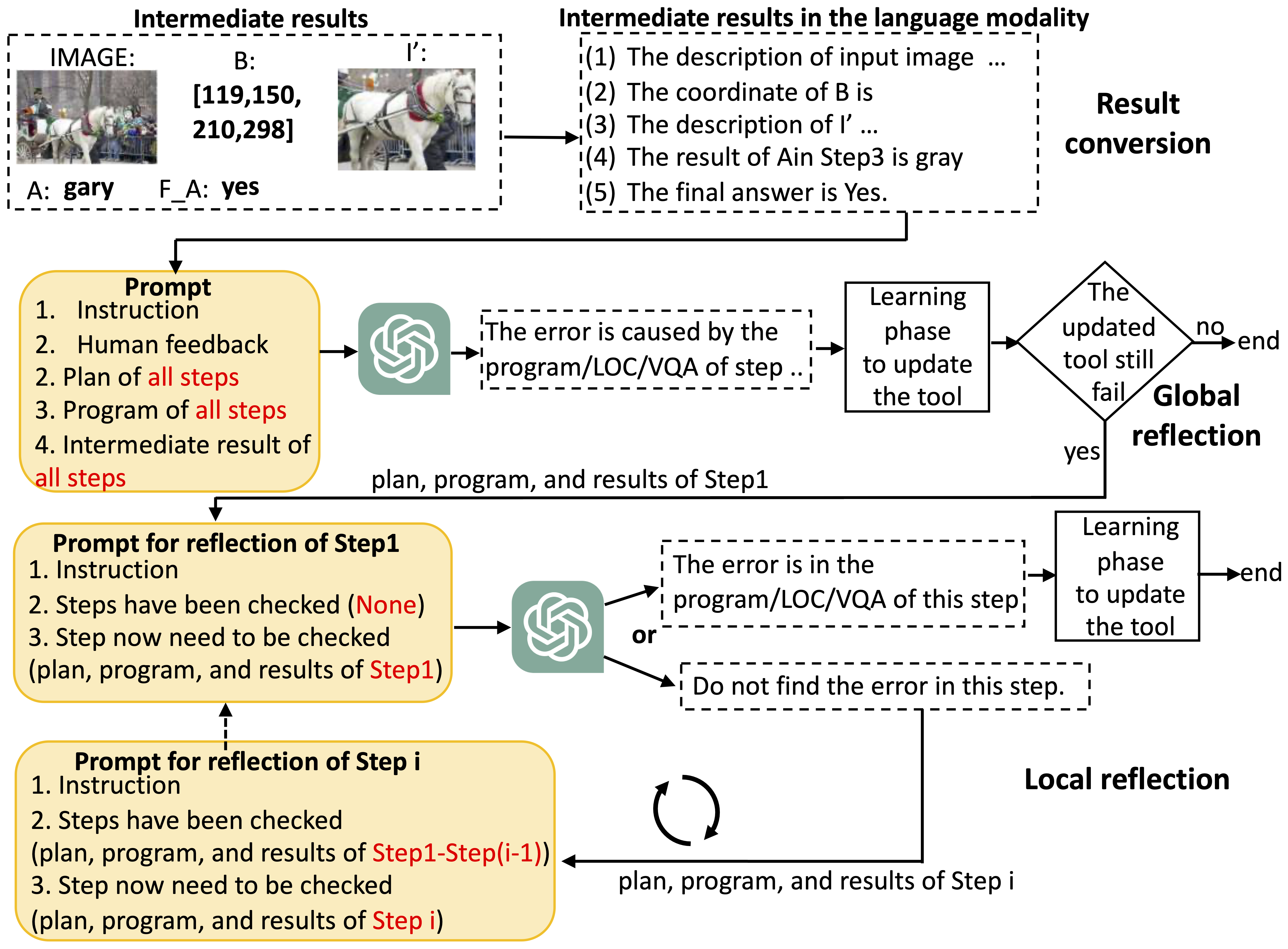
Utilizing large language models (LLMs) to compose off-the-shelf visual tools represents a promising avenue of research for developing robust visual assistants capable of addressing diverse visual tasks. However, these methods often overlook the potential for continual learning, typically by freezing the utilized tools, thus limiting their adaptation to environments requiring new knowledge. To tackle this challenge, we propose CLOVA, a Closed-Loop Visual Assistant, which operates within a framework encompassing inference, reflection, and learning phases. During the inference phase, LLMs generate programs and execute corresponding tools to complete assigned tasks. In the reflection phase, a multimodal global-local reflection scheme analyzes human feedback to determine which tools require updating. Lastly, the learning phase employs three flexible approaches to automatically gather training data and introduces a novel prompt tuning scheme to update the tools, allowing CLOVA to efficiently acquire new knowledge. Experimental findings demonstrate that CLOVA surpasses existing tool-usage methods by 5% in visual question answering and multiple-image reasoning, by 10% in knowledge tagging, and by 20% in image editing. These results underscore the significance of the continual learning capability in general visual assistants.
 CLOVA: A Closed-LOop Visual Assistant with Tool Usage and Update
CLOVA: A Closed-LOop Visual Assistant with Tool Usage and Update